
Este blog es un resumen extendido del articulo Riascos, A. (2025).1 Desde el inicio de la llamada tercera ola de redes neuronales (Goodfellow et al., (2016)), en la primera década de este siglo, se ha generado una gran esperanza en las posibilidades de la inteligencia artificial para transformar todas las actividades humanas. Asimismo, se han levantado alertas sobre los riesgos que conlleva la introducción de esta nueva tecnología (Bengio et al., (2024)). Con la introducción de ChatGPT en 2022 por parte de la empresa OpenAI, las expectativas han crecido exponencialmente y las mejores estimaciones sobre el impacto económico de dichas tecnologías son asombrosas. Por ejemplo, McKinsey (2023) estima que el potencial valor agregado anual de la analítica avanzada, el aprendizaje de máquinas y el aprendizaje profundo2 puede estar entre 11 y 17.7 billones de dólares (y 2.6 a 4.4 billones adicionales si incluimos el potencial impacto de la inteligencia artificial generativa). Estas son cifras descomunales si las comparamos con el valor agregado mundial en 2022, que fue de aproximadamente 101 billones de dólares. Cuando se analiza por sector económico, se estima que en el sector público y social el valor agregado puede estar entre 70,000 millones y 110,000 millones de dólares (o 0.5% – 0.9% de los ingresos del sector). Estas estimaciones parecen conservadoras para el sector público pues solo miden los ingresos del sector e ignoran el impacto que este tiene sobre todos los sectores de la economía. De cualquier forma, todo parece indicar que aquí existe una gran oportunidad para agregar valor al sector público en forma de mayor productividad, ingresos, transparencia, etc., con muchas externalidades positivas para la economía y la sociedad en general.
En este contexto, este articulo tiene como principal propósito aportar algunos ejemplos de aplicaciones concretas del aprendizaje de máquinas a diferentes problemas en el sector público colombiano y, cuando sea posible, discutir su potencial impacto económico. Es también una oportunidad para discutir brevemente las principales razones por las cuales algunas de estas aplicaciones no se han implementado, resaltar las dificultades políticas, organizacionales, etc. Las aplicaciones que se presentan son al sector de salud pública y seguridad ciudadana.
Salud Pública: Ajuste de Riesgo
En el primer caso, se muestra como el uso de técnicas de aprendizaje de máquinas podría mejorar sustancialmente el modelo de ajuste de riesgo con el que se compensan todas las aseguradoras en salud de Colombia (Empresas promotoras de Salud – EPS). Por ejemplo, mejorar la predicción del quintil más costoso de los afiliados al régimen contributivo pasando de una predicción de 29% del gasto con el modelo actual, al 43% usando un modelo de aprendizaje de máquinas. Esto reduce sustancialmente los incentivos a la selección de riesgos de las aseguradoras. En la Tabla 1 se muestran los resultados de utilizar diferentes modelos de aprendizaje de máquinas y variables independientes. El modelo que se usa actualmente para hacer el ajuste de riesgo es básicamente el primero: WLS UPC (weighted least squares). Esta tabla muestra el RMSE, MAE, R² y las razones predictivas anualizadas y no anualizadas en la muestra completa. La primera columna muestra los parámetros con los que se entrenaron los modelos basados en aprendizaje automático. Para las redes neuronales (ANN), el primer número corresponde al número de neuronas en la capa interna y el segundo es el parámetro de decaimiento del peso. Para el modelo de bosque aleatorio (RF), el número indica la cantidad de árboles, y para el modelo de boosting árboles (GBM), corresponden a la cantidad de árboles, la dimensión de las interacciones de variables, los parámetros de contracción y el número mínimo de observaciones en nodos no terminales, respectivamente. “Two stages” indica que el modelo incluye la probabilidad de reclamar un servicio y “FS” que el modelo se ajusta sobre el conjunto de variables seleccionadas utilizando la selección de características. El RMSE y el MAE se reportan en pesos colombianos de 2011. Además de las diferencias entre los modelos de aprendizaje de máquinas, existen diferencias en las variables utilizadas. UPC quiere decir que se usan las mismas variables que utiliza el MSPS. Dx significa que se usan 29 grupos de enfermedades de larga duración (Riascos et al. (2014)3), H una variable de número de días de hospitalizaciones previas, E vistas al especialista, U días en unidad de cuidados intensivos y Demos son solo variables demográficas. Finalmente, FS corresponde al uso de un modelo de selección de variables. Los resultados que se muestran son únicamente para el quintil más costoso de todos los afiliados al sistema contributivo. El mensaje principal de esta tabla se encuentra en las dos últimas columnas. En estas se muestra que modelos como GBM con todas las variables predicen el 43% del gasto anualizado del quintil más alto (50% del gasto no anualizado) en comparación con el 29% del modelo del MSPS (33% del gasto no anualizado). Esto quiere decir que los modelos de aprendizaje de máquinas pueden disminuir considerablemente los incentivos a la selección de riesgo, haciendo una mejor predicción y asignación de recursos hacia los afiliados más costosos del sistema. Como se demuestra en el articulo, esto no viene a expensas de un mayor gasto, ya que la predicción del gasto agregado es muy similar al gasto realizado en toda la distribución.

Tabla 1: Desempeño de varios modelos fuera de muestra en el quintil más costoso del gasto. Fuente Riascos et al (2012),
Salud Pública: Hospitalizaciones Prevenibles
De la misma forma, se podrían obtener reducciones significativas en los costos del sistema si se usara un modelo de predicción y decisión sobre las hospitalizaciones prevenibles. Los datos utilizados para esta aplicación son similares a los de las aplicaciones anteriores, una muestra de 5.7 millones de afiliados al régimen contributivo entre 2009 y 2011.
La siguiente Figura 1 muestra la curva ROC (Receiver Operating Characteristic) y en el recuadro el área bajo la curva ROC de la predicción, con un año de anticipación, de si una persona va a ser hospitalizada o no. En todos los casos, las variables son básicamente las mismas de la base de suficiencia con algunas interacciones. Una forma de interpretar el área bajo la curva ROC es la siguiente. Por ejemplo, el mejor modelo de la figura es un bosque aleatorio con un área bajo la curva ROC de 0.93. Esto significa que si se usa el modelo de RF para estimar la probabilidad de que una persona sea hospitalizada el próximo año, llamemos a esto el score de hospitalización, si elegimos al azar una persona que en efecto no va a ser hospitalizada y elegimos otra persona al azar que sí va a ser hospitalizada, entonces con una probabilidad de 0.93 el score de la persona que no va a ser hospitalizada es menor que el de la persona que va a ser hospitalizada. Estos resultados son muy buenos y comparables con los que se reportan en la literatura.
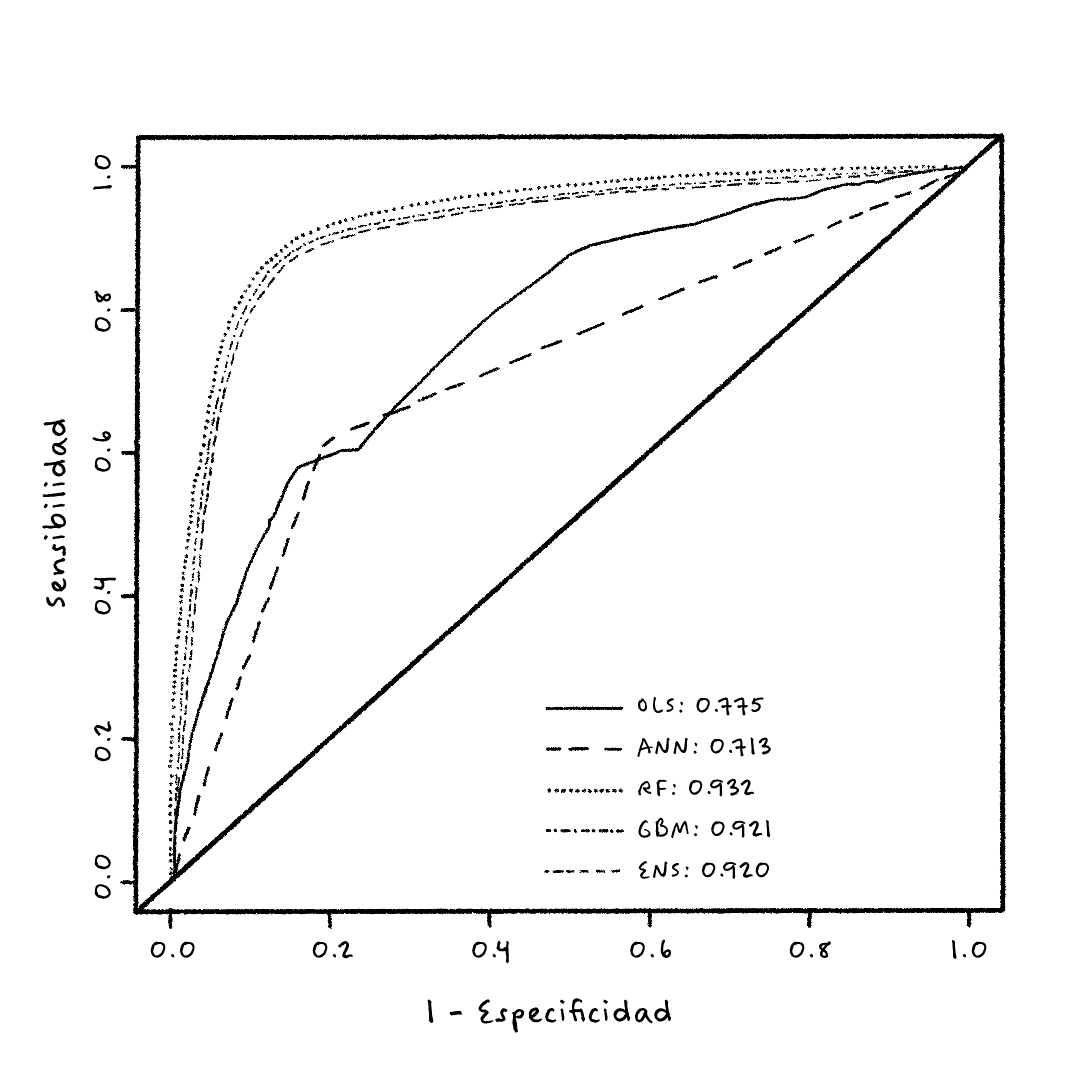
Figura 1: Curva ROC y Área bajo la curva ROC de diferentes modelos para predecir si una persona a ser hospitalizada. Fuente: Riascos et al. (2018).
Ahora, lo más interesante es ver cómo se puede usar este modelo en la toma de decisiones de las aseguradoras con el propósito de disminuir los costos de la prestación del servicio de salud sin sacrificar la calidad del servicio. Para esto, se implementó un modelo de decisión que hace lo siguiente: supongamos que una visita domiciliaria tiene cierto costo fijo (eje x en la siguiente Figura 2) y que medimos la efectividad de la visita con un parámetro entre cero y uno que reduce en esa proporción la probabilidad de ser hospitalizado el próximo año. Finalmente, de la base de suficiencia podemos estimar el costo de una hospitalización. Ahora, el modelo compara el costo esperado de ser hospitalizado, teniendo en cuenta la probabilidad que el modelo de aprendizaje de máquinas le asigna a la persona, el costo y la efectividad de la visita, y lo compara con el costo esperado de la persona sin visita domiciliaria. Cuando el primer costo es menor, entonces se toma la decisión de hacer la visita domiciliaria. Por ejemplo, si el modelo de aprendizaje de máquinas estima que la probabilidad de que una persona vaya a ser hospitalizada el próximo año es del 80%, el costo esperado de ser hospitalizado es COP $2,000,000 (estimado de la base de suficiencia), la eficacia de la visita es del 40% y el costo fijo de la visita domiciliaria es COP $500,000, entonces el costo esperado después de la visita domiciliaria sería: 80% x 60% x $2,000,000 + $500,000 = $1,460,000. Ahora, sin visita domiciliaria, el costo esperado de esa persona es: 80% x $2,000,000 = $1,600,000. Luego, en este caso, el modelo de decisión recomienda hacer la visita domiciliaria con un potencial ahorro para el sistema de COP $140,000.
Si hacemos este cálculo para todos los afiliados del sistema, podemos determinar en qué casos es costo-efectivo, en valor esperado, hacer una visita domiciliaria y prevenir una hospitalización innecesaria. La siguiente figura estima el ahorro esperado, al agregar sobre todos los afiliados, al implementar una política de prevención cuando es costo-efectivo versus no hacer nada. Este ahorro se presenta en la siguiente figura como una función del costo fijo de la intervención y la eficacia. Por ejemplo, para un costo de la intervención de COP $500,000 y una eficacia del 50%, el ahorro en valor esperado es $50,000 por afiliado. En 2011, la UPC era aproximadamente $500,583, luego el ahorro representa básicamente el 10% del costo del sistema. Una cifra nada despreciable.
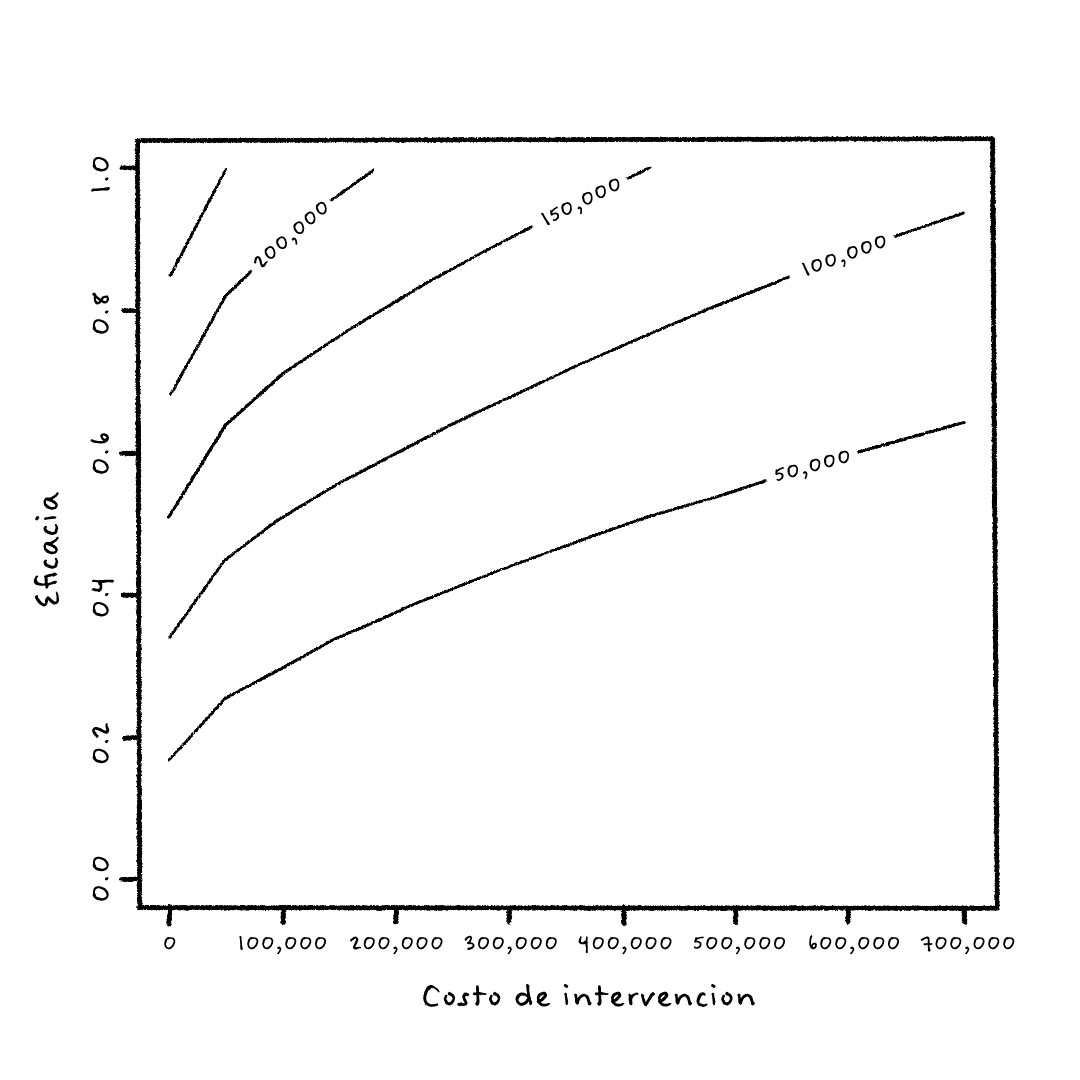
Figura 2: Curvas de nivel con el ahorro estimado de diferentes combinaciones de eficacia y costo de intervención. Fuente: Riascos et al. (2018).
Seguridad Ciudadana
Las siguientes aplicaciones son dos trabajos seleccionados de un proyecto de investigación que se financió con recursos de regalías y fue ejecutado en cooperación con la Secretaría de Seguridad de Bogotá, la Universidad Nacional de Colombia y Quantil. Un ejemplo exitoso de alianza entre el sector público, la academia y la empresa privada.4 El proyecto abarcó varios temas relacionados con el crimen en la ciudad de Bogotá: predicción del crimen, interpretabilidad de los modelos de predicción, sesgos de los algoritmos construidos, estimación del subregistro de eventos y la asignación óptima de la policía en la ciudad, entre otros. Fueron más de veinticuatro productos científicos, todos utilizando técnicas de aprendizaje de máquinas.5 En este capítulo se describen dos que consideramos entre los más interesantes: la asignación óptima de la policía y la cuantificación del subreporte de datos de crimen.
Impacto del Patrullaje en el Crimen y Asignación Óptima de la Policía
Uno de los principales problemas con los modelos de predicción del crimen es que estos ignoran la reacción estratégica de los criminales. Para resolver este problema, utilizamos los resultados de un experimento social a gran escala en la ciudad de Bogotá (Blattman et al. (2021)) y un modelo estructural de localización del crimen (es decir, un modelo de elección discreta) para identificar el impacto causal de las patrullas policiales sobre el crimen. Una vez identificado el efecto causal, planteamos un problema de optimización para minimizar el crimen en la ciudad asignando de forma óptima a la policía en diferentes puntos de la ciudad.
Una ventaja de usar modelos estructurales es el hecho de que se pueden construir escenarios contrafactuales. El resultado más importante es, por lo tanto, la estimación del impacto causal de diferentes estrategias de patrullaje policial (la asignación de tiempo en todas las ubicaciones de la ciudad). En particular, se puede estimar el tiempo de asignación, sujeto a una restricción de tiempo agregado invariante, que resulta en la mínima cantidad de crimen. En resumen, el artículo muestra que, si la policía se asignara de forma óptima de acuerdo al modelo, habría una reducción agregada del 7% en crímenes violentos, 8.5% en crímenes contra la propiedad y 5.2% en el total de crímenes. Esta reducción en el crimen, especialmente en el crimen violento, es muy importante desde un punto de vista social y, aún más importante, porque proviene de una asignación más eficiente del tiempo policial en lugar de costos adicionales.
Seguridad Ciudadana: Subreporte del Crimen
Así mismo, se introduce una técnica para estimar la verdadera cifra del crimen en la ciudad dado que, en términos generales, es de esperar que exista un subreporte considerable de estas cifras (dark figure of crime).
Esta aplicación está basada en Riascos et al. (2023). El punto principal del artículo se centra en la introducción de algoritmos de aprendizaje que estiman lo que en esta literatura se llama la cifra oscura del crimen. El subreporte de eventos socialmente sensibles como el crimen puede socavar la credibilidad de las cifras oficiales y puede ser utilizado estratégicamente por agentes oficiales o el público en general. Por eso, los modelos que estiman simultáneamente la incidencia y las tasas de subreporte de eventos pueden ser utilizados para mejorar la asignación de recursos públicos. Por ejemplo, en el año 2021, la encuesta de victimización y reporte de la Cámara de Comercio de la Ciudad de Bogotá reportó una tasa de victimización promedio del 17% y, entre estos, solo el 49% dijo haber reportado el evento a la policía.
Para estimar el grado de subreporte del crimen en Bogotá, utilizamos una forma de aprendizaje de máquinas conocida como bandido multiarmado (i.e., un caso particular de lo que se conoce como aprendizaje por refuerzo). En esencia, el método se basa en distribuir el recurso policial en la ciudad de tal forma que en los lugares que visitan puedan hacer una buena recolección de información sobre el crimen. Cada día, la policía se despliega en la ciudad donde hay más posibilidades de encontrar un crimen, pero también ocasionalmente visita otros lugares de forma aleatoria. La estrategia está en hacer esta explotación (visitar los lugares con mayor evidencia hasta el momento de crimen) y exploración (visitar aleatoriamente ciertos lugares) de forma óptima.
La siguiente Figura 4 muestra los crímenes violentos agregados mensualmente según lo reportado en las estadísticas oficiales de la ciudad (línea roja SIEDCO). La línea azul muestra los crímenes violentos agregados según lo reportado al centro de llamadas de emergencia y seguridad de la ciudad (línea azul NUSE). La línea Total es la estimación del verdadero crimen en la ciudad. Esta se construye a partir de SIEDCO y NUSE, como se explica en el artículo, pero lo importante resaltar es que es totalmente independiente de la metodología de bandido multiarmado,
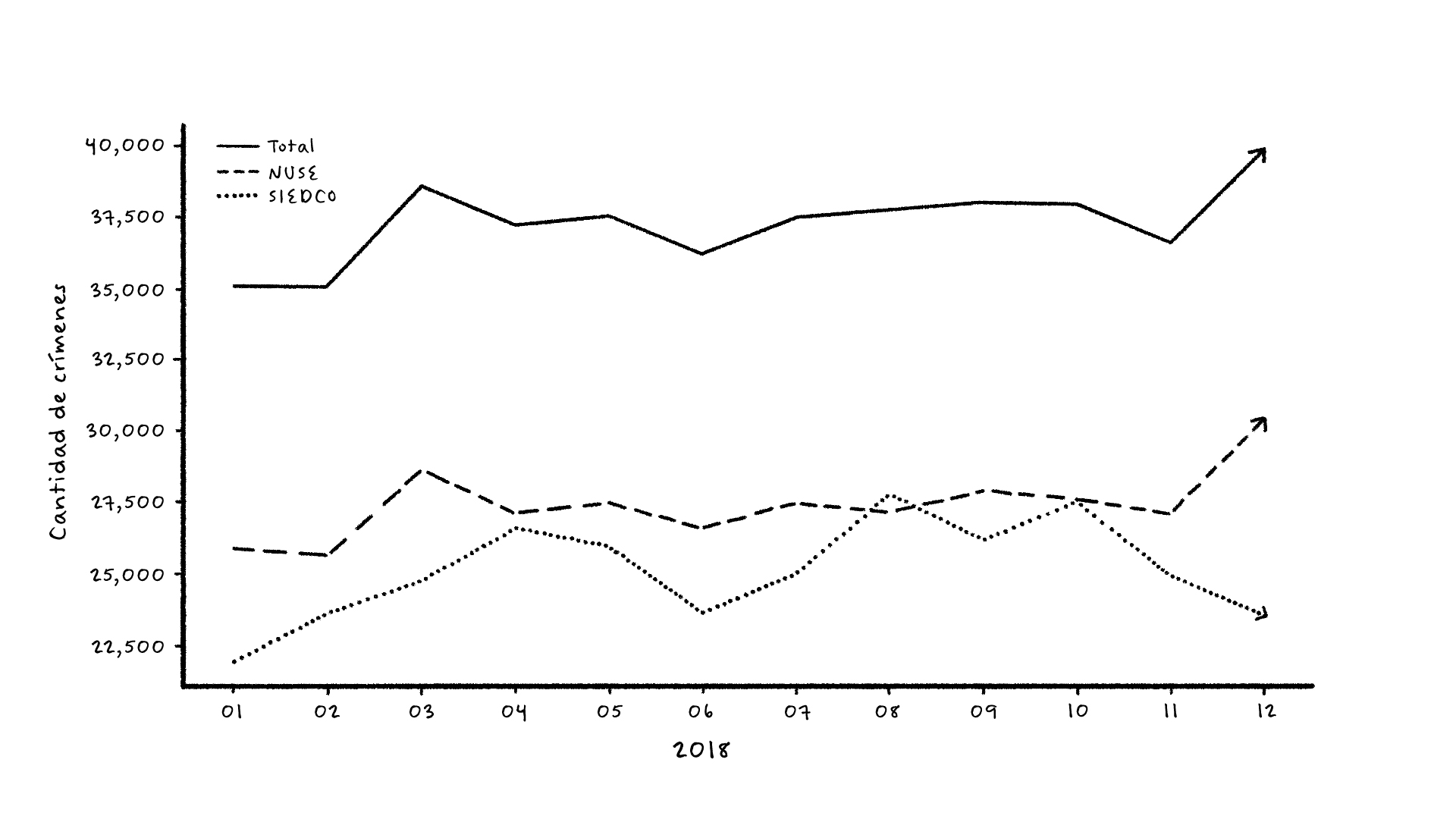
Figura 4: Crimen descubierto (línea roja), crimen reportado (línea azul) y estimación del crimen total en la ciudad de Bogotá. Fuente: Riascos et al. (2023).
La Figura 5 muestran cómo el mejor algoritmo propuesto (CUCB) descubre el número agregado de crímenes en la ciudad (figura de la izquierda) y el resultado para el subreporte de crimen (figura de la derecha). La restricción importante es que en cada período como máximo se permite visitar el 10% del área de la ciudad. La verdadera incidencia y las tasas de subreporte deben compararse con la estimación metodológicamente independiente de la Figura 4. “Total” es la estimación de la verdadera cantidad de crímenes, y “NUSE” es la estimación de los crímenes reportados.
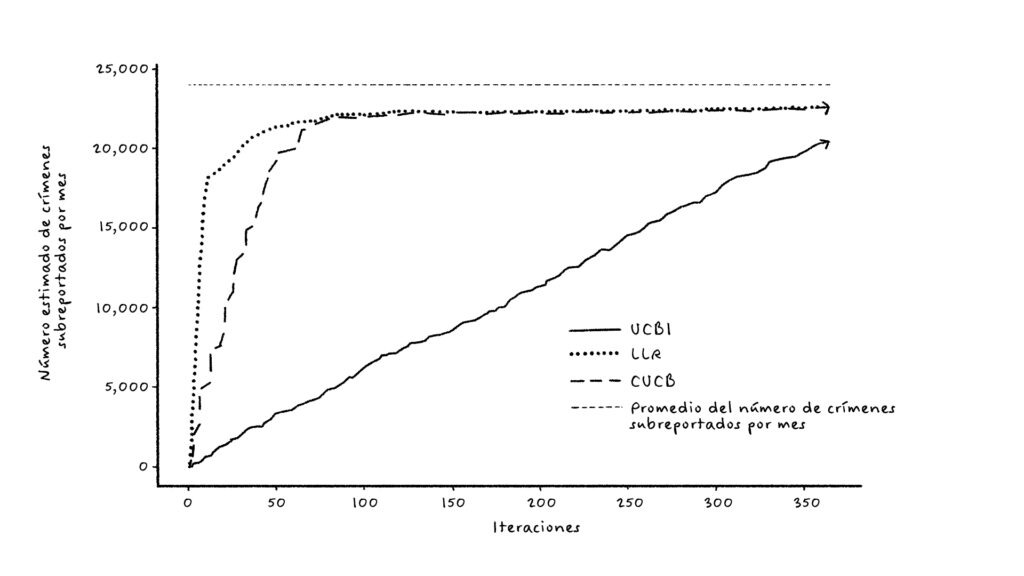
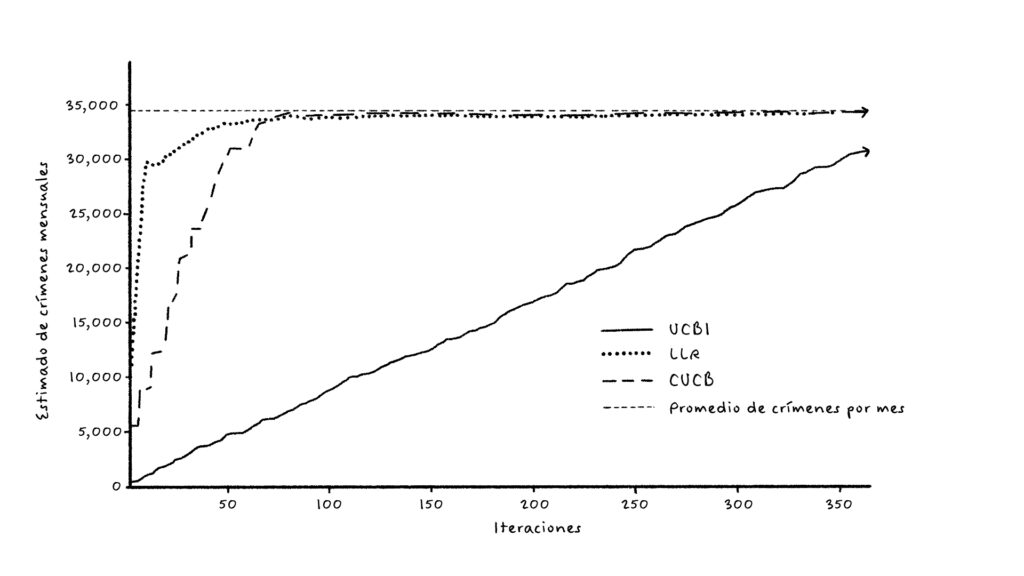
Ilustración 5: Estimación del crimen y crimen reportado (subreporte) para Bogotá usando el algoritmo CUCB para bandidos multiarmados combinatorios. Fuente: Riascos et al. (2023).
Reflexiones finales sobre la implementación y conclusiones
Las aplicaciones anteriores son una selección personal del trabajo que en Quantil y yo, como profesor de la Unuversidad de los Andes, hemos venido realizando en el sector público en la última década. Por razones de espacio quedan por fuera aplicaciones valiosas en el Departamento de Impuestos y Aduanas (DIAN), el Departamento Administrativo Nacional de Estadísticas (DANE), el Ministerio de Tecnologías de la Información y Telecomunicaciones (MinTIC), la Agencia Nacional para la Defensa Jurídica del Estado (ANDJE), el Departamento Nacional de Planeación (DNP), el Banco de la República (Banrep), la Comisión de Regulación de Telecomunicaciones (CRC), multilaterales como el Banco Interamericano de Desarrollo (BID), empresas mixtas del Estado como Ecopetrol, etc.
Ahora, al reflexionar de manera más amplia sobre estas otras aplicaciones y el papel de la analítica en el sector público colombiano, es necesario mencionar que una de las experiencias más decepcionantes para un científico social es ver cómo su trabajo puede terminar siendo totalmente ignorado. Aunque esta no siempre es la experiencia general, los proyectos presentados en este capítulo, considerados proyectos bandera, relevantes y con un alto potencial de impacto, son justamente ejemplares por no haberse concretado o, en el mejor de los casos, solo parcialmente. Sin duda, hay lecciones para aprender de cada caso particular, pero estas reflexiones finales se concentran en aprendizajes generales y transversales.
Hace unos años, conversando sobre esta frustración con un profesor de la Universidad de Carnegie Mellon en Estados Unidos, me comentó que él usaba dos estrategias para mitigar ese problema. La primera era involucrar fuertemente a los usuarios del sector público que tuvieran relación con el desarrollo para que el proyecto y los resultados positivos fueran también logros de un equipo interno. Nada más válido que esto, y hay muchas razones para ello. Como cualquier empleado en una organización, su carrera se beneficia de mostrar logros útiles para su organización, pero, a diferencia del sector privado, en el sector público los salarios suelen ser menos atractivos que en el sector privado y existen menos recursos para invertir y generar conocimiento internamente. Un proyecto de aprendizaje de máquinas suele ser un proceso relativamente avanzado y, si no se puede exhibir como un logro personal, no hay incentivos para defenderlo. Además, presentarlo y defenderlo como si un tercero hubiera podido hacer algo valioso para la institución sin recibir crédito probablemente es poner en duda la calidad de su trabajo, que puede haber sido de muchos años en una entidad pública. Es decir, el mérito debe ser de un equipo que incluye a todos los que sea necesario para que, al menos, se considere su implementación. En caso contrario, sería cuestionar el trabajo interno de años. Esta es, sin lugar a duda, una condición necesaria para el éxito.
Ahora, no dejan de ser un problema otras características del servicio público: muchos empleados entran y salen con el gobierno de turno, quienes toman decisiones tienen intereses políticos, y cuando se trata de implementar una política que afecta a la sociedad, es raro que todos ganen o que ganen por igual. Esto hace que la toma de decisiones sea riesgosa (e.g., una fórmula de ajuste de riesgo más precisa sin duda beneficia a varias aseguradoras que están siendo mal compensadas por los riesgos que asumen, pero igualmente afecta a aquellas que han sido sobrecompensadas de forma ineficiente). De igual forma, no es raro que los técnicos de una entidad pública sean reemplazados por activistas políticos con una visión completamente distinta del papel del Estado, el valor de la ciencia, etc. Por último, cuando se trata de soluciones que afectan o dependen de varias instituciones, surgen nuevos problemas, pero a una escala mayor. Una institución (o departamento dentro de una institución) quiere ser la primera en aportar soluciones innovadoras (así no tenga nada que mostrar) e ignora lo que la otra hace (esto ha sido en parte el problema con la implementación de algunas aplicaciones mencionadas en este capítulo).
Más allá de los egos, a un nivel más técnico, todo se puede complicar porque las instituciones no comparten su información, existen riesgos legales y de privacidad y, en ocasiones, es todo fruto de la falta de tecnología para hacerlo. De ahí la importancia de los proyectos de interoperabilidad de los datos en el sector público y de la implementación de técnicas que, con un margen de confianza alto en un sentido probabilístico, permiten compartir información agregada sin comprometer la identidad de las entidades involucradas o información sensible (e.g., como usar alguna forma de privacidad diferencial).
Lo segundo que me mencionó fue que, si ocurre que la solución es buena y fuera de toda duda agrega valor desde el punto de vista de una política pública, pero no hay ambiente para su implementación, ¡acaba con ellos en los medios! Por razones obvias, nunca he practicado esta estrategia, aunque hay que reconocer que en ocasiones la tentación es grande.
Para terminar, a manera de conclusión, las aplicaciones que aquí se han mencionado no solo agregan valor al ejercicio de diseñar políticas eficientes para la sociedad, sino que motivan al sector a tomar cada día mejores decisiones basadas en datos, a modernizarse en el uso de tecnologías y a mejorar su capital humano. Por supuesto, ninguna tecnología nueva llega sin generar sus propios riesgos y problemas, pero en la medida en que estos riesgos tengan origen en la utilización de algoritmos, existe la posibilidad de entenderlos y posiblemente aprender a mitigarlos.
- El Potencial Impacto del Aprendizaje de Máquinas en el Diseño de las Políticas Públicas en Colombia: Una década de experiencias. Universidad de los Andes. Disponible en: https://hdl.handle.net/1992/76101 ↩︎
- Todas estas se consideran subáreas de la inteligencia artificial que se caracterizan por el uso intensivo de datos, algoritmos y capacidad de cómputo. En este capítulo, abusando un poco del lenguaje, se usará el término “aprendizaje de máquinas” para referirse a este conjunto de técnicas, excluyendo la inteligencia artificial generativa, para la cual no se aportan ejemplos de aplicaciones concretas al sector público colombiano. ↩︎
- Para mayores detalles, el lector puede consultar Riascos et al. (2014). Sin embargo, el punto clave a resaltar aquí es que estos grupos fueron construidos con la ayuda de expertos en salud. ↩︎
- Diseño y validación de modelos de analítica predictiva de fenómenos de seguridad y convivencia para la toma de decisiones en Bogotá. BPIN 2016000100036, recursos regalías. ↩︎
- Para más información sobre este proyecto, el lector puede consultar https://centroanaliticapp.org/proyectos/crimen/ y los artículos científicos pueden encontrarse en https://www.alvaroriascos.com/crime/ y https://sites.google.com/site/fagomezj/personal. ↩︎



No Comments